AI Determinism for Source Code Generation
LLMs are great plugins for sketching some code. We already have plugins that you put in a high level description and they deterministically produce lower level code: they're called compilers. Computer science & software engineering would not exist without them.
This quote is paraphrased from a recent interview by Cory Doctorow.
The thought of AI LLMs as just another plugin finally crystalised the correct view of current LLM technology for me... they're just another tool that turns higher level language into lower level code.¹
LLMs as "Compilers"
So LLMs take in higher level (natural) language and produce lower level code. But...
We're Not Committing the Source Code?!⁴
When writing C or Python you commit the C code, or Python, or whatever to the code repository, and that code runs through a deterministic compiler or run time to produce a repeatable result, usually producing some much lower level code.
With LLMs, as far as I know,⁵ most/all people are not committing all the raw higher level natural language inputs. This means that the "source code" is missing from the repository. So you have no way of re-running the high level natural language "source code" through an LLM again to recreate the output code because those prompts are not being saved.
That usage of LLMs is obvious because of how LLMs work and how inefficient it would be to have them recompile the whole code base every time you wanted to make a tiny change. But it's also a fundamentally different model to any programming that has gone before and not in a good way that allows for repeatability, reliability or in fact any ability to understand what the raw inputs were that shaped the current code base.
If we took that same approach with C or Python we'd be saving the blobs of machine code and calling the C or Python compilers to produce new iterations of that machine code and Python bytecode.
Non-Determinism
Secondly, and this has been talked about a lot, the LLM "compilers" are effectively non-deterministic. That means that even if I was committing all of my prompts to the "code" repository and sharing that with you, you would have no guarantees of the LLM "compiling" the same program.
Even if we made LLMs deterministic there's no standard implementation with a list of tests describing how they should perform given certain input.
I could see it might be possible to make such a standard but then it would inherently severely limit the power of an LLM as that is precisely the flexibility of their systemic architecture which is so valuable.
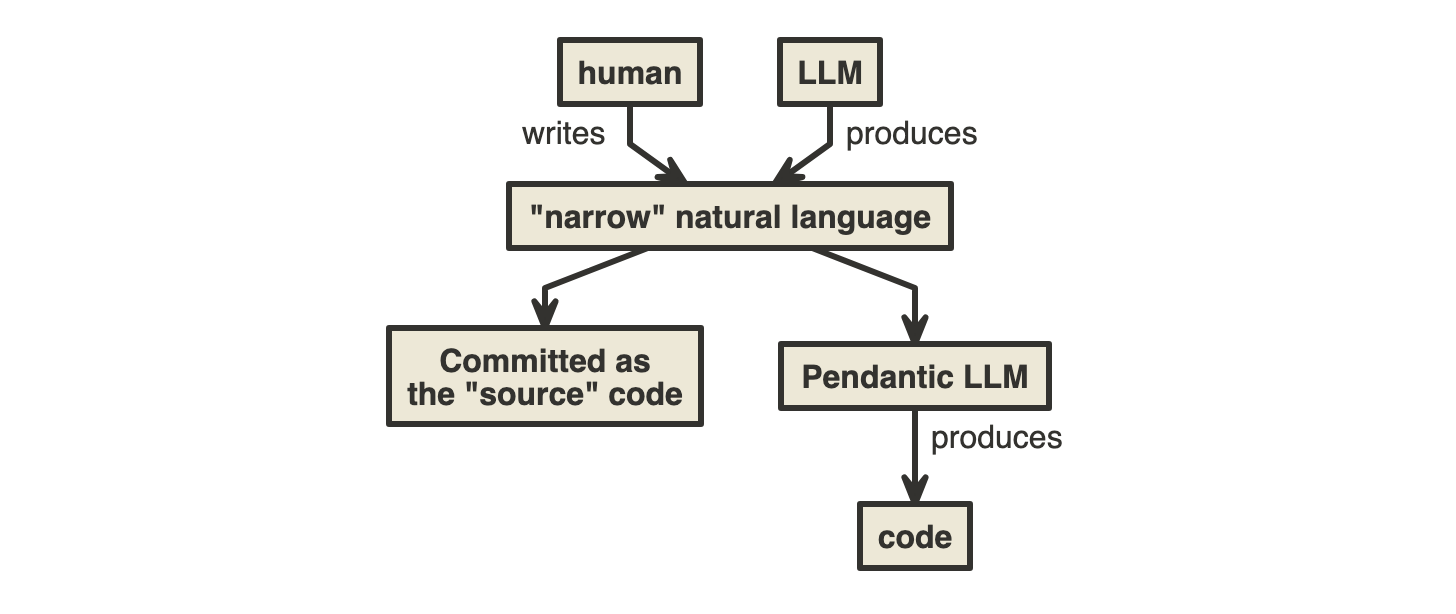
"Narrow" Natural Language as an Intermediary?⁶
Perhaps another approach would be to have the following architecture that uses two LLMs, one that is more general and flexible but which is used to produce more narrow, structured, pedantic natural language (Controlled Natural Language - thanks ChatGPT) that is designed to be committed to the code base and used through a deterministic LLM to generate all the lower level code:
*the "narrow natural language" would be committed to the repository and act as the source of truth for the code base. The "normal" code would be generated at build / run time from this "narrow natural language" code through a deterministic LLM process. This development pattern would still prevent the user from directly editing the code.
LLM (Last LLM Maintained)
This is less relevant if LLMs stay generalised but if some of the problems above can be addressed and they do specialise then the question of "Which LLMs will remain maintained?" is an important one.
A repository of natural language "source code" that was compatible with one specific specialised LLM process would not necessarily yield the same results if run through a different LLM process. i.e. the LLMs that remain would be incompatible with that "source code" and thus be unable to work on it deterministically until it was converted over.
Notes
¹ I find it fascinating how difficult it is to not fall into the trap of imbuing the LLM responses with more weight / any intelligence than they should be given. The responses are so human-like and flexible that I can see the big danger for many people getting very confused when they follow confident answers and end in harm's way. I want all humans and all beings to be as flourishing as possible (even if from a purely self centered perspective this is good for everyone else) so others coming to harm is NotAGoodThing™️.²
² Just after writing this I read Stuart Kirk's FT article "What you said about my new ChatGPT investment adviser" and saw exactly this happening to him. He claimed you could prompt an LLM with:
In practice, even the least sophisticated saver can type: “Hey look, I haven't a clue about finance, but I want to go on cruises and stuff until I die. Can you help?” At which point an AI agent takes over — analysing bank accounts, risk tolerance via questionnaires, tax status, family situation, health records and so on.
Except the quality of the response is dependent - in a complex way - on the quality of the prompt as is well known and as I recently demonstrated here with >300% 4x(!) difference in answers depending on the smallest of changes to the prompt.
⁴ I can imagine this already discussed somewhere and perhaps people have even tried to commit all the prompts for a LLM to be able to rebuild the whole project from? Would seem an expensive thing to do given the current performance of LLMs.
⁵ Please correct me if I'm wrong, thank you.
⁶ I can also imagine this already articulated somewhere. According
to ChatGPT it's being explored as "Controlled Natural Languages (CNLs)"
which predate the current LLM era. So I'd be curious to know what's
changed in that field of research and if CNLs are a lot closer to being
realised?