Sub-citations for efficient recall and validation of references
We already use sub-citations for books and legal documents, why not academic / scientific papers?
We already use sub-citations for books and legal documents, why not academic / scientific papers?
A flood of unstructured data in PDFs
During the early months of the Covid-19 pandemic, I was fortunate to be employed by CCI to analyse data from Covid-19 diagnostic EUAs (Emergency Use Authorisations) being rolled out in the USA. At that time, there was a flood of new diagnostics emerging, with a poor understanding of what was being approved: both strategically and for the general public.
At a strategic level, there was confusion around which genetic targets were being used, at what sensitivity (limit of detection), which control materials were used for validation, and whether the purported validations were robust (sometimes they definitely were not). At a consumer and general public level, there was uncertainty about which diagnostic tests could be obtained, from where, and what they could and could not tell you about this evolving infectious disease to help keep yourself, your loved ones, and your community safe.
The FDA (Food and Drug Administration) was publishing Emergency Use Diagnostics on an often daily basis. These PDFs regularly ran to many tens of pages, and the PDFs themselves were of mixed quality and all with different formatting. Several groups, including CCI, were analysing these PDFs and extracting data from them as we wrote about in our latest paper.
Extracting structured data from PDFs
At CCI, I wanted to continue existing work structuring the EUA PDF data [1][2] by extracting several additional data fields and covering a larger proportion of the EUAs being published. Initially this was an entirely manual process: searching the PDF to locate relevant data points and claims before copying and pasting those into a spreadsheet.
After only a handful of these I had some rows of a spreadsheet. Each row had the name of a diagnostic test, a manufacturer's name and the relevant fields of data but no easy way for myself or the team to double check my work... I might have just located the one or two important characters in a document averaging around 30,000 characters, sometimes up to 165,000 characters, and yet I did not have an easy way to mark that point in that specific PDF and make it trivial for myself or others to find it again in the future... validation was not going to happen quickly or at all.
This looked like an opportunity to me.
Anot8.org
As my friend Jimme Jardine showed me with Qiqqa, annotations enable powerful information recall, so I set to work building a bare bones prototype which is now hosted on Anot8.org (as of October 2020).
Anot8.org, together with its local Python powered server, allowed me to load a PDF, annotate an area of it, adding a comment and or manually copy and paste its text content, apply labels and then have a permanent URL that addresses both the PDF and one or more specific annotations:

Trivial structured data validation and analysis
After this labelling was performed it was now trivial to both link to, recall, validate and analyse these structured data annotations. As shown in the table "SARS-CoV-2 Test EUAs data table" in this write up Insights from Structured SARS-2 Diagnostics Data, every single value that makes up each cell (sometimes multiple values) is referenced to a specific point in each PDF. For example that screenshot above comes from clicking this link in the table:
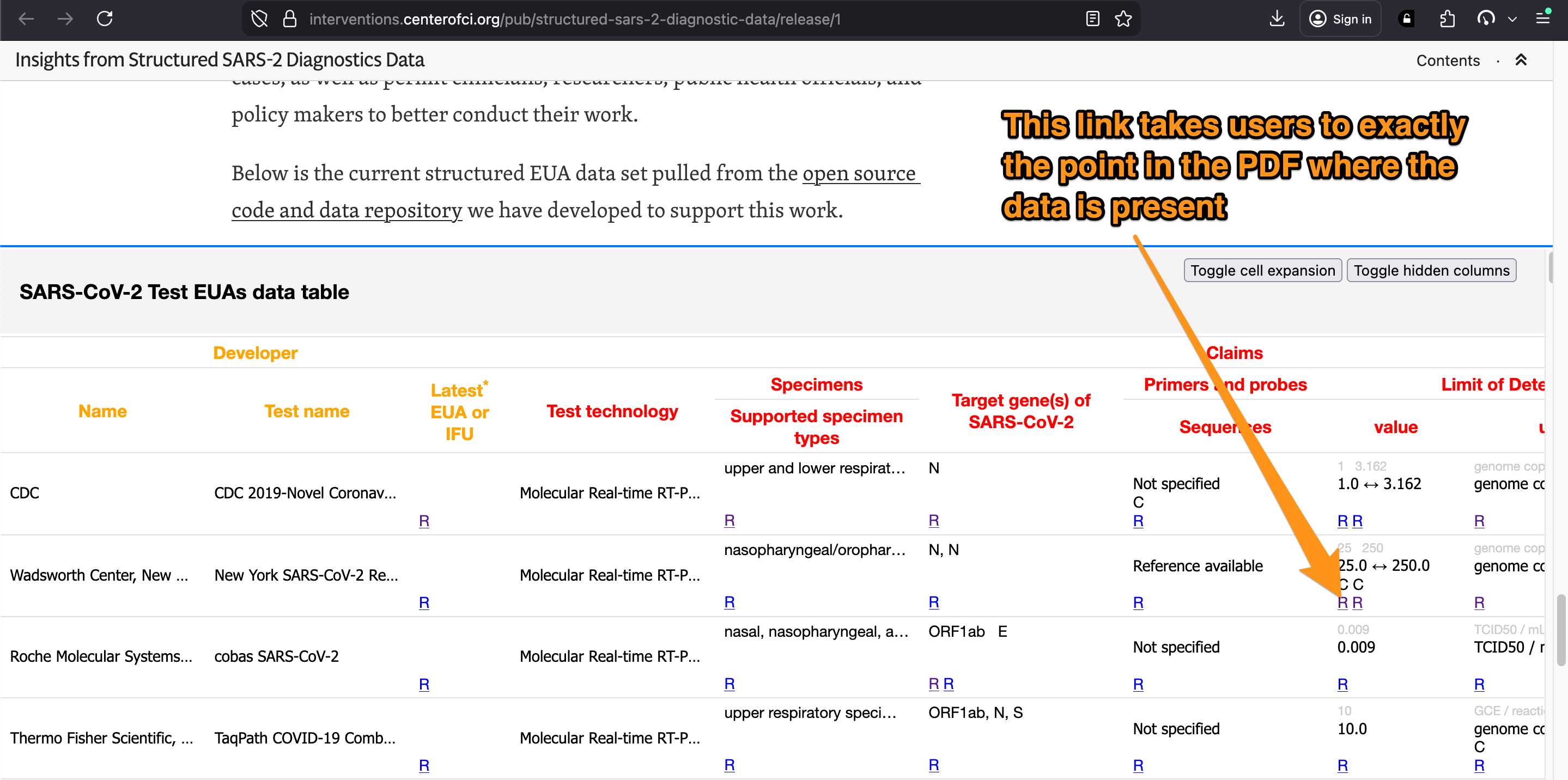
All of the data, reference links and the HTML in that table was generated from the stored PDF annotations with only a simple set of command line scripts.
I like to refer to these reference links as sub-citations. We have them for legal documents, acts of parliament / congress and book references. Why don't we have something similar for academic PDFs?
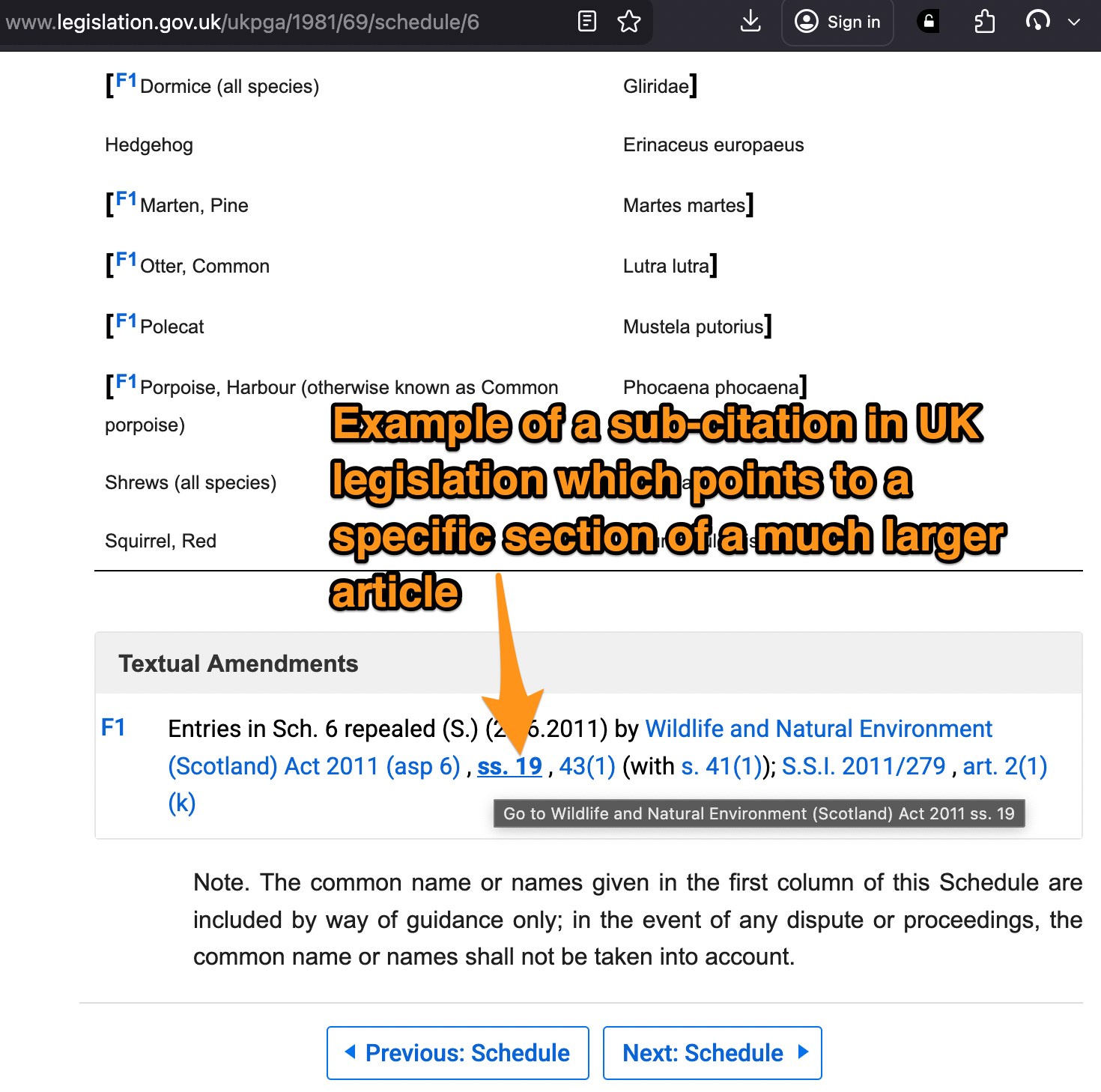
Referenced legislation (which happens to be a fairly decent sub-citation by itself but with the Text Fragments supported by Firefox browsers this highlighting function is very good, and if it automatically scrolled the page to the highlighted text, it would be spot on! legislation.gov.uk/ukpga/1981/69/schedule/6#:~:text=ss.%2019)
Sub-citations as standard for academic papers?
References in academic articles sometimes refer to an entire body of work. Often though, a reference is really only pointing to a key finding, claim, graphic, table, or even a single word or data point. Instead of referencing a whole document often with many tens of papers, why don't we start to use annotations and build a 4Ps (@anil.recoil.org) sub-citations commons infrastructure?
Yes for some cases a versioned / deterministic LLM might be suitable for finding the specific parts of documents being referenced, but given their computational cost, time, planetary resources and current lack of deterministic result in comparison to a plain URL, why don't we start using sub-citations?
You can actually already do sub-citations with Anot8.org for free: all you do is provide a URL to a PDF and then once it loads, annotate part of a document and copy the resulting URL just like this: https://anot8.org/r/?doi=10.1371%2Fjournal.pone.0160589&url=https%3A%2F%2Fjournals.plos.org%2Fplosone%2Farticle%2Ffile%3Fid%3D10.1371%2Fjournal.pone.0160589%26type%3Dprintable&h=0-ajp&ta=%5B%5B0%2C11%2C%22%22%2C%22The%20frequency%20with%20which%20people%20physically%20move%20throughout%20the%20day%2C%20even%20if%20that%20movement%20is%20not%20rigorous%20exercise%2C%20is%20associated%20with%20both%20physical%20health%20and%20happiness%22%2C%5B%5D%2C%22285.5%22%2C%22215.5%22%2C%22581.5%22%2C%2246%22%2C%22AJP%22%5D%5D
I'm sure there are already better options available, or that could be built with minimal investment.
As an aside, the anot8.org application already provides a rudimentary name space so that anyone else who wants to host more permanent and discoverable annotations online can do so by submitting a single-line pull request to the repo.
Quantifying sub-citation benefits
As I discussed with many CCI folk at the time, and with Samuel J Klein, but alas I have not yet prioritised: we could do a trivial piece of research showing the benefits of sub-citations.
Hypothesis: sub-citations would significantly reduce the time taken for someone to validate a reference is supporting a claim superficially i.e. the reference is at least relevant to the text it relates to.
Method: Randomly assign a group of researchers to one of two groups. Get two paragraphs of text. Group A has the first paragraph with normal references and the second with sub-citations. Group B has it round the other way with the first paragraph having sub-citations and the second having regular references. Give each group a list of assertions to validate from each paragraph. Time how long it takes them to submit a validation and whether they performed it correctly.
Samuel, myself, and others think this is a no-brainer. But it would be good to see the research done and the result published somewhere. If you're interested then let's chat: @ajamesphillips.com.
Sub-citations might also disincentivise the practice of reviewers requesting their own work be cited when it has minimal relevance to a specific paper or claim.
What's blocking sub-citations from happening?
Why have we not offered them before to our fellow scientists, academics, funders, policy makers and general public? Certainly some technical barriers have lowered: Mozilla's PDF.js was essential for Anot8.org, and Text Fragments are still not uniformly implemented in browsers. But with regard to journals being the only gate keepers for formats of papers, what about progressive forward thinking journals who might want to adopt, provide and perhaps even insist on sub-citations for new manuscripts? What examples of sub-citations / annotations already in use in the wild can be leveraged and grow adoption of sub-citations from?